Learnings from ingesting millions of technical pages for RAG on Azure.
Context overview
This document outlines insights of an engagement with one of our partners.
The Engagement revolved around an AI Orchestrator as a backend for a copilot for digital twins, in the context of highly-technical documentation. The reasoning engine makes use of the RAG (Retrieval Augmented Generation) pattern to ground answers. At the core of RAG is search, and at the core of search are indexes.
One of the major pillars of the engagement was the milestone to index ~200k documents within 7 days, while chunking, embedding and enriching the search index items. A final run involving roughly 230k documents (about 8 million chunks) took just over five days to complete given the customer constraints (on a single AKS pod, limited only by a single embeddings deployment).
The list below is subjective. Your mileage may vary.
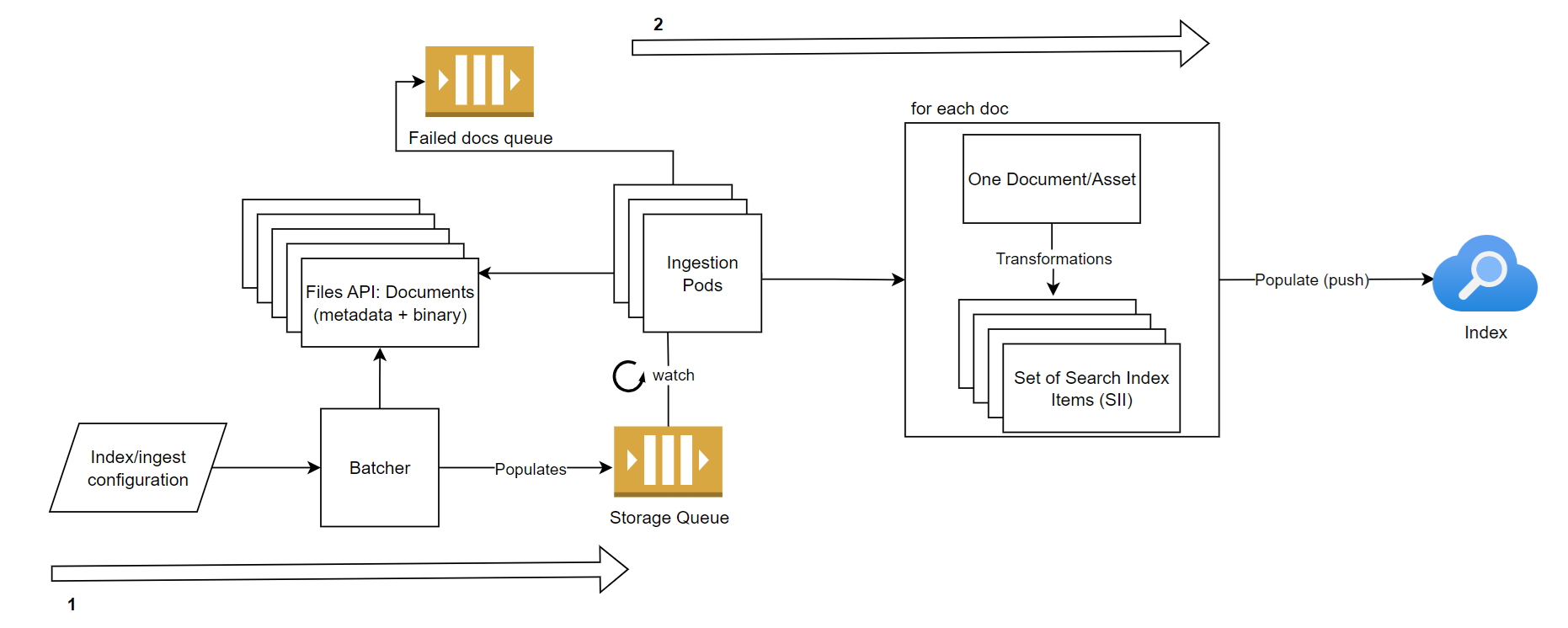
Ingestion abstracted/high level architecture
The images below roughly describe the ingestion process.
In short: create batches, add them to a queue, dequeue them in pods running in AKS (Azure Kubernetes Service), transform them into search index items, push the items to Azure AI Search. Transformations require external services such as Azure OpenAI, Document Intelligence, ...
List of learnings
The following list is a collection of insights, largely unordered, from the past six months:
Azure AI Search
- Important: When using Hybrid Search, if you rely on your the full-text
search_textargument to find matches in documents, be aware that unmatching documents can still be returned due to vector search. Detailed writeup here. - The cost of Azure AI Search is largely determined by the amount of storage you require.
- Given the above, choosing an embedding model with a smaller vector size can be interesting, since it allows for more items to be stored.
- We started out with
text-ada-002which has dims 1536. Later on in the engagement, we started usingtext-3-largewith dims 256. On April 3rd 2024 the pricing of Azure AI Search changed increasing the storage of most pricing tiers, so this is possibly less relevant now.
- We started out with
- You can use indexers to load data (pull-model), e.g., from blob storage, into indexes. This works quite well.
- You can run multiple indexers on the same index at the same time for a near linear (!) performance increase.
- There is a maximum number of indexers per search service, so this may constrain you.
- Skillsets can enrich documents during the run of an indexer. We were not fan of this, and were advised against it by other colleagues. Just let an indexer do the indexing, and prepare your search index items in such a way they are fully ready (enriched) to be indexed at the time of indexing.
- If you prepare your search index items as JSON before indexing, you can batch them into a JSON list, which an indexer can parse, and is more performant.
- Ensure that if you are indexing from blob, the blob is in the same region as the search service. We had to find out the hard way. In our case, the performance difference was ~7x.
- You can run multiple indexers on the same index at the same time for a near linear (!) performance increase.
- Pushing to index directly from your pod is also quite performant, and in our case was the preference due to data retention constraints. However:
- Caution: Batch-pushing to Azure AI Search can result in a 207 mixed response, but this does not actually mean all items are pushed to the index successfully.
- You'll encounter the 207 status code(RFC), which is a mixed response, but it does not mean all items are actually pushed to the index. This is only noticeable if you push a LARGE amount of items to the index concurrently, so can easily be overseen and missed. Resolve this by checking if every result (e.g., from the push call using the python SDK) has status "succeeded".
- Caution: Batch-pushing to Azure AI Search can result in a 207 mixed response, but this does not actually mean all items are pushed to the index successfully.
Reading, chunking, search index items:
- Reading and chunking (PDF) documents is closely intertwined. For instance: keeping track of page numbers during reading and chunking, keeping track of document structure, etc., requires your reader and chunker to be 'collaborating'.
- Determining a structure (chapters, headers, semantically relevant chunks) from reading PDFs is difficult, especially if your documents are not uniformly structured.
- Document Intelligence (DI) is a powerful tool for reading documents (e.g., PDF binary to text), but it can be expensive. Alternatives (e.g., PyPdf, or full-fledged libraries as unstructured) may work, but the results may be worse.
- Document intelligence offers various models for reading, such as prebuilt-layout, prebuilt-reader. Their costs vary quite a lot (10x for read v.s. layout).
- Prebuilt-layout allows for converting PDF to Markdown, which could be interesting for chunking purposes as it allows you to add information about the structure of the documents prior to embedding. From word-of-mouth, I understood this feature doesn't work great.
- DI only accepts up to 2k pages at a time. Neatly splitting up the document and reconstructing/stitching the responses(a proprietary AnalyzeResult instance) afterward such that the text offsets/pages are correct was an open issue for us.
- At the time of implementation: The DI Python SDK did not feel fully mature yet. For instance, we wrapped the reader's poller in custom async logic as async was not supported at the time, and the poller logic for timeouts did not work well for us.
- Recently, Document Intelligence added detailed documentation specifically for RAG purposes.
- We had various success with various chunkers. Since we have a diverse set of documents, we needed one which works regardless of the incoming documents.
- A custom implementation of Langchain's RecursiveCharacterTextSplitter performed best for us, with a chunk size of 2000 and 200 overlap.
- We experimented with adding summaries, key phrase extraction from Azure AI Language to enrich the search index items. We found this to be rather expensive (it would account for >50% total costs) for no clear added benefit for search results, although we did not run thorough experiments on this.
- Chunks used for embeddings are used for finding relevant documents. Chunked used to answer questions are used for grounding. Their purpose is different, so they could be different sizes - we did not implement this, but I recommend looking into it.
- Consider adding extra information on top of chunks prior to embedding to improve the semantic relevance of the chunks.
Embeddings:
- Figuring out the performance of various embedding models is difficult, because evaluation is very difficult (see below). The MTEB Leaderboard can be a relevant reference to see the performance of a variety of embedding models in a variety of use-cases.
- Embeddings can be used for more than just search. For instance, the location of embedding of a chunk in the latent space can be used in synthetic QA generation.
- The Token-Per-Minute rate (TPM) of Azure OpenAI Embeddings was our bottleneck in our ingestion process. We used strict retry policies with exponential backoff to manage this (there are cleaner ways, see DAPR point in Misc.).
- While it won't help with TPM limits, consider batch-sending your embeddings. Keep track of the number of tokens in a batch (e.g., using
tiktoken) and send batches which are just shy of the max token limit per batch to reduce the number of calls.
- While it won't help with TPM limits, consider batch-sending your embeddings. Keep track of the number of tokens in a batch (e.g., using
- Hosting your own embedding models (e.g., in a pod on AKS) is possible, and we experimented with it. Try it out if it seems relevant to you.
Evaluation:
- Why evaluate your RAG solution: on one hand it is a way to steer the ship: it allows you to answer questions as: what should my chunk-size be, which embedding model to use, is my search working as expected, etc.
- Evaluation is complex, and should be part of the core of your RAG solution.
- Conversely, the ability to quantify the performance of your copilot informs actions and enables ongoing monitoring of the solution (e.g., to detect drift in the implemented solution).
- You should differentiate between using evaluation for search quality optimization (retrieval, or how relevant are your found results given a query?) and end-end optimization (generation, how well does the full RAG pipeline work?).
- Using LLMs for evaluation is a valid approach, and although much discussion exists on this, most of the metrics we used are LLM-based (do consider costs with many LLM calls!).
- Start early with creating and generating datasets you can use to evaluate
- A golden dataset can be created in collaboration with end users of the solution. Ensure you have means to be able to create, and verify this golden dataset
- You can create a 'silver' dataset synthetically - there are various ways to do this.
- An interesting approach found by a data scientist on our team was to cluster chunks in the embedded space, and to ensure that we generate synthetic QA pairs from a sample representing the set of clusters in the embedded space, to ensure our sample represents the various types of possible questions.
- The validity of synthetic QA pairs needs to be verified.
- A rudimentary (dated) approach to generating QA pairs is described in one of my old posts here.
- Ensure you know what it means for a metric to change across evaluation runs. Consider what happens if the variance of the evaluation results is too large. This means that it is hard to find a (statistically relevant) relationship between changes made in your RAG pipeline and changes in your evaluation results. Thereby, it becomes hard to steer your RAG solution based on these results.
- If the cost (monetary or practical, such as the ability to run the evaluator, or the availability of a quality golden dataset) of running evaluations is high, it decreases the opportunity for developers to make informed decisions when building various parts of the RAG solution.
Python (library, dev practices, misc)
- Async generators are powerful. We found them especially useful in preparing documents to be transformed into search index items, and pushing them to the index. Only at the final step would the tasks be executed. I'm sure there are better (or more pythonic ways), but I was quite happy with the technical ease and performance of the approach.
- (Async) context managers are powerful, especially in a context where you are managing services which need to be close()'ed.
- As an example of the previous point: Our customer required custom logging rules for easy parsing within their Grafana dashboard. Libraries do exist for this, but KISS: in a few LoC, we built our own pretty logs + logger context manager which wraps around whatever needs to be timed and logged. The
__exit__method of the context manager allows us to change the behavior depending on if the running function raised:
def __exit__(self, exc_type, exc_val, exc_tb):
"""Exit the context manager."""
if exc_type: ... # log the error, otherwise log 'finished' as normal- Consider using the azure-openai-simulator for simulating calls to Azure OpenAI Services in addition to e.g., Document Intelligence for (unit/integration) tests.
- If you are using an
aiohttp.ClientSession, consider setting up a session manager with a singleton pattern, as it is recommended to use a single session in the lifetime of your application, and it makes testing easier. - We had a version mismatch between Pydantic 1.X for a shared library, and 2.X for the ingest service. This was 'temporarily solved' using a compatibility wrapper and put on the backlog. This came to bite us when it broke Friday afternoon just before planning to do a large ingestion run. Don't do this.
- If you're looking to write performant python code, I managed to get a significant speedup (~5x) simply by profiling using
cProfileand improving our async/concurrent approach. It was definitely worth the effort, and worth looking into.
Miscellaneous
- Summarizations: for summarizing (large) documents, we found that the following approach worked well for us: if the total contents is smaller than the context window, use all contents to generate a summary. Else, with N=total tokens, use N/2 tokens of the start of the document, and N/2 tokens of the end of the document to generate the summary. For documents exceeding the context window, this resulted in the following costs and speeds:
| Model | Tokens | Time | ~Cost |
|---|---|---|---|
| GPT3.5-turbo | 8k | 11.4s | $0.005 |
| GPT3.5-turbo | 16k | 12.8s | $0.009 |
| GPT4-turbo | 8k | 22s | $0.10 |
| GPT4-turbo | 16k | 26.24s | $0.19 |
| GPT4-turbo | 32k | 47s | $0.35 |
For smaller documents, with <20 pages, it take less than 2 seconds to summarize.
- Storage is cheap, reading + embedding can get expensive. Consider caching your search index items, and only updating the index items partially whenever that is possible.
- You can follow a simple 'delta'-update flow for efficient updates, such as: first, check if the index configuration (e.g., embedding model) has changed. If yes, full-update documents. If not, check if only a field has changed (e.g., a metadata field) as opposed to the contents of the PDF/Document (binary). To check if the contents have changed before reading them using (expensive) Document Intelligence, you can use heuristics like last-changed, or do an MD5 check after loading the document binary.
- Consider using prompt compression techniques if you need to reduce your context size. We found that we were able to compress the context by 1.2x - 3x with only slight decreases in our evaluation metrics.
- If you want to quickly get up-and-running with a RAG solution, one "Microsoft" approach would be to explore prompt flow. For productionizing, further customizing and maturing a solution, other approaches might be more suitable for your use-case.
- Using our ingestion pod approach, we were able to scale up to 8 pods simultaneously without any problems with any of the services except for the embeddings endpoint. When scaling you should be mindful of retry policies interfering with each other.
- The architecture shown at the top is rather 'monolithic' - an alternative would be a solution like Dapr - Distributed Application Runtime. It would allow us to have more control over e.g., queues between steps of the ingestion process, and mitigate issues such as aggressive retry-backoff in-code for when multiple pods start exceeding the embedding endpoint quota. While we experimented with this approach, it was not the best fit for our customer.
Comments
No comments yet.
Stored via Netlify Functions & Blobs. Do not include sensitive info.