Disclaimer: I am an employee at Microsoft ISE. However, the views and opinions are of my own.
We have recently engaged in an architecture design & upskilling session with an enterprise customer for building a solution using an LLM as part of their reasoning engine. Their aim is to utilize this to assist engineers in navigating complex technical documentation. This is a collection of some of the learnings:
On orchestrators: To professionally develop, test, and deploy your LLM product in an enterprise environment, you need an orchestrator for your LLM service. In our case, we want our orchestrator to allow us to extract user intent, execute one or multiple functions, and return a reply to the end-user generated by an LLM using the built context. One challenge, however, is that there are quite a few orchestrators available. A somewhat biased and non-exhaustive list includes langchain, azure semantic kernel, an internal Microsoft orchestrator, GUI alternatives such as Azure Machine Learning Promptflow, and my personal orchestrator built for PoCs and avoiding OpenAI subscription costs. Perhaps we need a standardized LLM orchestrator:

On statelessness and prompts: Given the above, lets take a step back and question why we even would need an orchestrator. An orchestrator is essential for orchestrating evaluation flows, allowing for modular and efficient development and defining (chained) prompts and functions. Most importantly, it allows us to manage our model context. From our practical point of view, an LLM like GPT-3.5 or GPT-4 is a stateless machine: every inference call is a new interaction. The only real action we can perform with an LLM is around the LLM: preparing the context or input, and processing the output it provides. This has given life to the art of prompt engineering, and while I do not think it should be a job title in isolation, it really does make a difference. To highlight: a demo by one of our product teams using a modified LLM revealed that the LLM's efficiency hinged majorly on the engineered system prompt. Apart from the system-, assistant-, and user prompts, we can feed our LLM with additional information, such as documentation search results, information about the (G)UI of the user, relevant metrics or other forms of data. Managing this context, especially considering practical constraints (like context window length), is vital as it essentially guides our LLM-powered ship.
On search: For building our context, we need to search and retrieve data. The popular term in an LLM context is RAG (Retrieval Augmented Generation). For our purposes, we are interested in retrieving information from various technical documents, diagrams, and sensors. These documents and data sources are used to build are context, which allows the LLM to answer the user question using domain specific knowledge. Typically, there are two approaches to searching: text-search and vector/semantic search. I assume you are familiar with the former, while the latter uses a learned embedding model to perform search based on similarity of documents.
Our tests with different vector databases, like FAISS and Azure Cognitive Search, showed no significant performance differences in preliminary tests. However, we noted that one lengthy document (a 3+ hour meeting transcript) was consistently favored by the embedded search, sidelining more relevant documents. Since this document wasn't especially pertinent to any of our queries, the context it built performed suboptimally. This points to the necessity of refining data pre-processing or ingestion for indexing in a vector DB. Microsoft introduces semantic search as an intermediary option, which does not use vector search outright. Lastly, hybrid search combines term and vector queries, leveraging different ranking functions and merging the results to provide a single ranked list of search results. For our customer engagement, we will likely opt for a hybrid model given the diverse plugins (functions, 'skills', etc.) we aim to support.
On intent extraction: Understanding user intent is crucial when aiming to execute functions like queries or metric retrievals. We've identified two primary methods:
-
LLM Direct Function Invocation:
- Process Overview:
- The LLM identifies possible functions to call.
- Determines which function aligns best with the user's intent.
- Returns instructions for that specific function call.
- Uses the function's response as part of the context when responding to the user.
- Visualization:
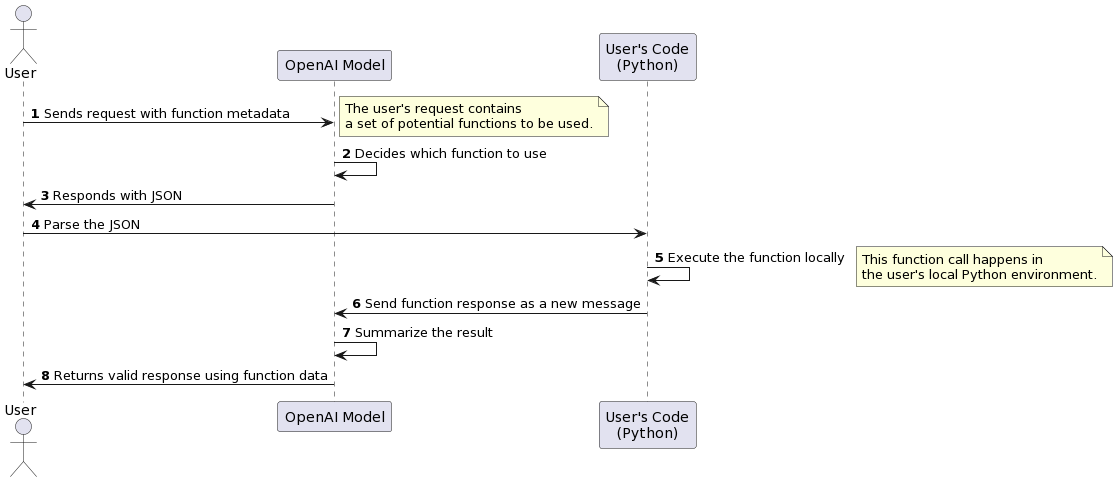
- Tools & Challenges:
- The output from LLM must be shaped into predefined JSON models to ensure functions can be called.
- While OpenAI Function Calling offers one approach, it isn't without issues. For instance, it can sometimes produce JSON not accepted by our function signatures.
- TypeChat is a Microsoft solution crafted to build natural language interfaces with types. Although there are methods to ensure LLMs generate valid JSON consistently, they aren't available for all GPT models.
- On that note, I'd recommend the library openai-functools which I co-developed. This tool auto-generates the necessary function (JSON) metadata for OpenAI, guiding the determination of which function to invoke based on the prompt. This approach is demonstrated in our Maintenance App Example showing the model is capable to determining which function to call best given the user prompt.
- Process Overview:
-
Mapping Intents to Functions:
- Process: The LLM identifies the user's intent from a predefined set based on the prompt. We then map this identified intent to specific functions, crafted from business logic. This logic might not always be directly transferrable or clear to the model's context.
- Example: An intent like "retrieve information from system ABC" might instigate several specific function calls.
On evaluation: Using one LLM evaluate the other is an interesting approach currently in use for an LLM used in in large scale production. One LLM generates multiple output to a query, and another (ideally larger) LLM rates the outputs of the resulting with a score between 0-1. It seems to work well for a product team with 500k+ generations/day, so it might suit others too. On construction of acceptance tests, since each LLM call is essentially a new call to a stateless machine, but you can construct each context fully before calling an LLM, you can evaluate a multi-step process easily by predefining the context for each step separately. Since each step in your process should either result in an output for a user, or a new context, each step can be evaluated in isolation. Finally, evaluation of natural language outputs can be challenging, but there have been some efforts to embed the output and use a closeness metric as an evaluation metric: embed the expected output and actual output, and measure their closeness in the latent space as the evaluation metric.
Comments
No comments yet.
Stored via Netlify Functions & Blobs. Do not include sensitive info.